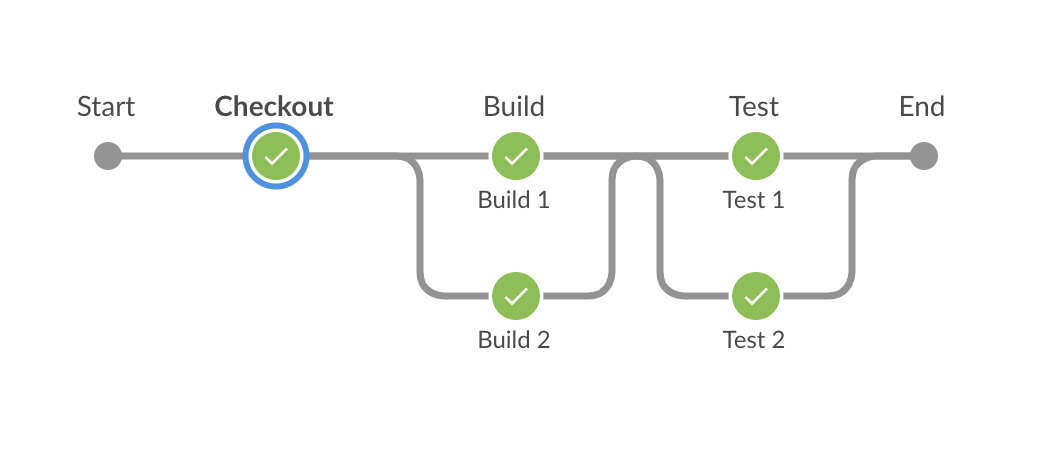
Jenkins Pipeline 在執行 Stage 時,某些情況使用平行處理可以節省很多執行所需時間,本文將會介紹幾種平行處理的方法。
你可以在官方文件中看到 Parallel 及 Matrix 兩種實現平行處理的方法,而我除了這兩個外還會在多介紹一個利用 Parallel 去實現動態 Stage 的方法,這也是很常在網路上看到的問題,可以更靈活地去運用 Parallel。
在開始之前先說明幾點,以下只討論 Declarative Pipeline,並在所有範例中使用 sleep(<sec>) 去模擬實際執行的時間。
Parallel
使用方法很簡單,只要利用 parallel 將要平行處理的 stage 包起來,並將其放置於一個 stage 中,而被包起來的 stage 就會以平行的方式執行。
語法範例
stage(<Stage 名稱>) {
parallel {
stage(<名稱>) {
// ...
}
stage(<名稱>) {
// ...
}
stage(<名稱>) {
// ...
}
}
}
注意事項
- 不能嵌套使用 (
parallel裡面不能再有parallel)。 - 一個
stage只能包含一個parallel,且這個stage不能再存在steps、stages或matrix。
基本使用範例
以下是執行結果與它的 Pipeline Script,可以看到被 parallel 包住的 stage 都有平行處理,且不一定只能有一個步驟。
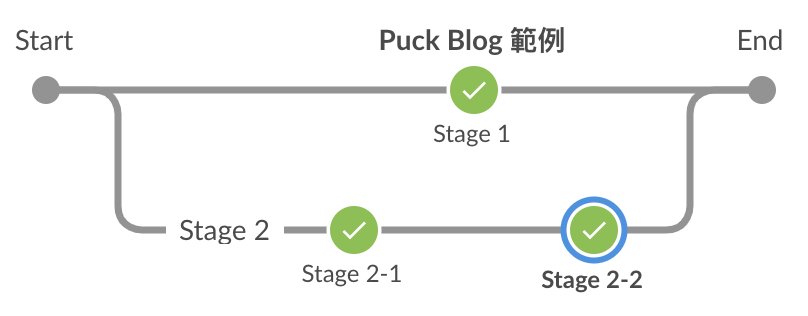
pipeline {
agent any
stages {
stage('Puck Blog 範例') {
parallel {
stage('Stage 1') {
steps {
echo "In Stage 1"
sleep(10)
}
}
stage('Stage 2') {
stages {
stage('Stage 2-1') {
steps {
echo "In Stage 2-1"
sleep(5)
}
}
stage('Stage 2-2') {
steps {
echo "In Stage 2-2"
sleep(5)
}
}
}
}
}
}
}
}發生錯誤時強制中斷
預設在 parallel 中有任意分支出現 stage 執行失敗時,只會中斷該分支執行,其他分支是不受影響。
所以如果想要在當有任意 stage 執行失敗時,強制中斷整個 parallel 的執行,可以加入 failFast 的設定來達到這個需求。
當 failFast 設為 true 時,只要有任意分支出現失敗,就會中斷整個 parallel 的執行,反之 (false) 則不會。
就算是已經在執行中的
stage也會被強制中斷!
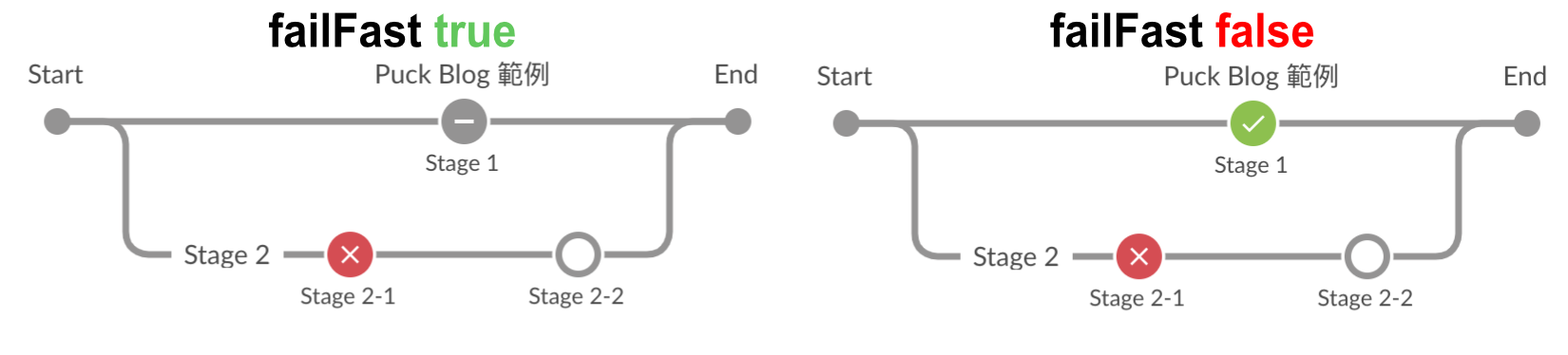
pipeline {
agent any
stages {
stage('Puck Blog 範例') {
failFast true
parallel {
stage('Stage 1') {
steps {
echo "In Stage 1"
sleep(10)
}
}
stage('Stage 2') {
stages {
stage('Stage 2-1') {
steps {
echo "In Stage 2-1"
sh 'exit 1' // 模擬發生了錯誤
sleep(5)
}
}
stage('Stage 2-2') {
steps {
echo "In Stage 2-2"
sleep(5)
}
}
}
}
}
}
}
}如果有很多個 parallel 不想每個都去單獨設定,可以在 Pipeline 的 options 加入 parallelsAlwaysFailFast() 即可。
pipeline {
agent any
options {
parallelsAlwaysFailFast()
}
stages {
}
}Matrix
跟 parallel 一樣式用於平行處理,不過 matrix 可以動態產生執行分支,相較一般的 (不寫 Script) parallel 方便許多。
如下語法所示,會有 matrix 來包住所有 Matrix 相關指令。其中 axes 是設定動態產生的資料,可以設定一個以上,執行時會列舉所有可能的組合來產生分支,並執行 stages 所設定的 stage,執行時也可透過設定的變數名稱取得對應的值。
例如我在 axes 中設定了 X=[A, B, C] 及 Y=[1, 2, 3] 那執行時變數列舉就會是 X=A, Y=1、X=A, Y=2… 共 3 * 3 次。更高維度的設定也是如此。
語法範例
matrix {
axes {
axis {
name <軸變數名稱>'
values <值>
}
}
stages {
stage(<名稱>) {
// ...
}
stage(<名稱>) {
// ...
}
stage(<名稱>) {
// ...
}
}
}
注意事項
- 不能嵌套使用 (
matrix裡面不能再有matrix)。 - 一個
stage只能包含一個matrix,且這個stage不能再存在steps、stages或parallel。
基本使用範例
以下是執行結果與它的 Pipeline Script,因為我在 axes 中有設定兩維的軸,所以會分四個分支,並可以看到在 stage 中可以取得該分支所對應的變數。
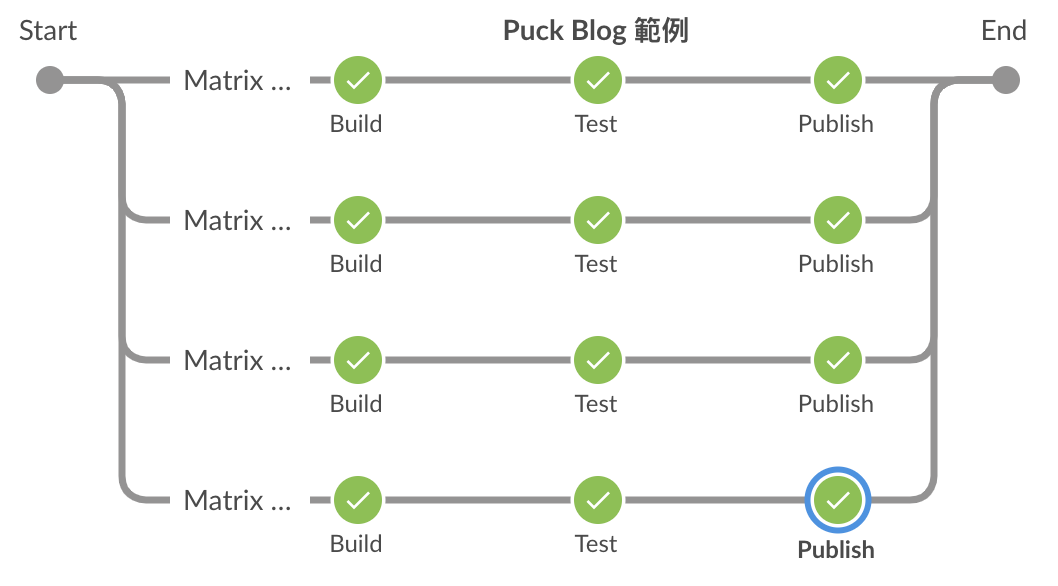
pipeline {
agent any
stages {
stage('Puck Blog 範例') {
matrix {
axes {
axis {
name 'PLATFORM'
values 'mac', 'windows'
}
axis {
name 'BROWSER'
values 'chrome', 'firefox'
}
}
stages {
stage('Build') {
steps {
echo "Do Build for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
stage('Test') {
steps {
echo "Do Test for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
stage('Publish') {
steps {
echo "Do Test for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
}
}
}
}
}排除某些組合
可以透過 excludes 來排除到某些組合不執行,下面這個例子就是將 safari / windows 的組合排除不執行,在執行時就可以看到只有五個分支而非六個。
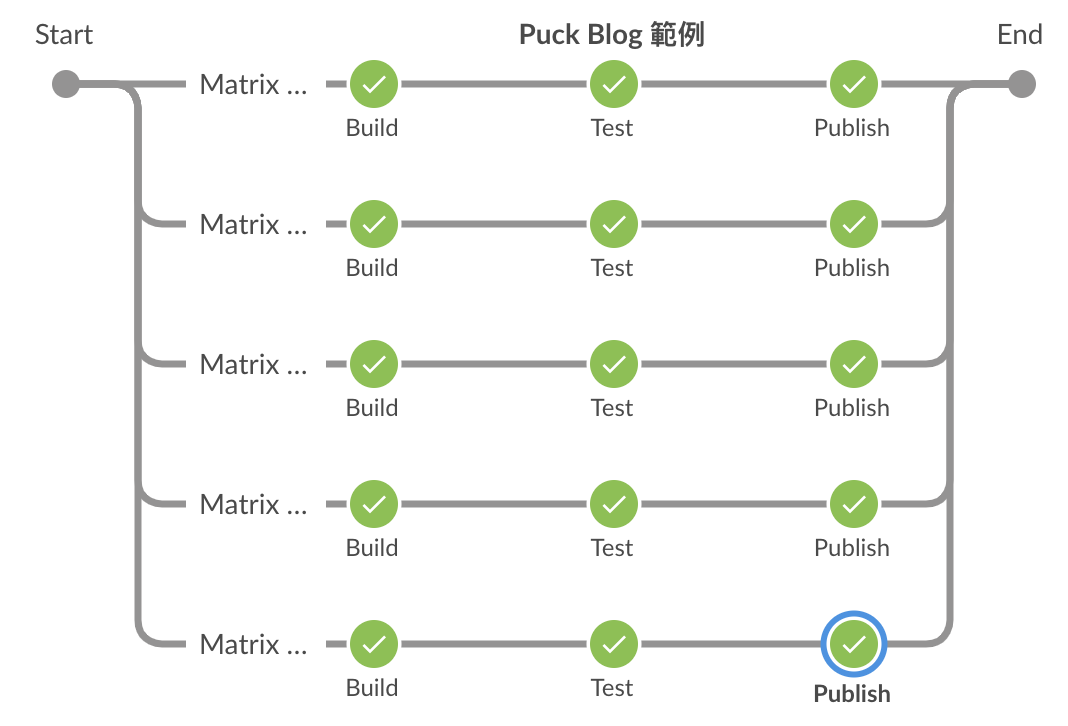
pipeline {
agent any
stages {
stage('Puck Blog 範例') {
matrix {
axes {
axis {
name 'PLATFORM'
values 'mac', 'windows'
}
axis {
name 'BROWSER'
values 'chrome', 'firefox', 'safari'
}
}
excludes {
exclude {
axis {
name 'PLATFORM'
values 'windows'
}
axis {
name 'BROWSER'
values 'safari'
}
}
}
stages {
stage('Build') {
steps {
echo "Do Build for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
stage('Test') {
steps {
echo "Do Test for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
stage('Publish') {
steps {
echo "Do Test for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
}
}
}
}
}發生錯誤時強制中斷
跟 parallel 一樣可以使用 failFast 去設定是否要強制中斷。
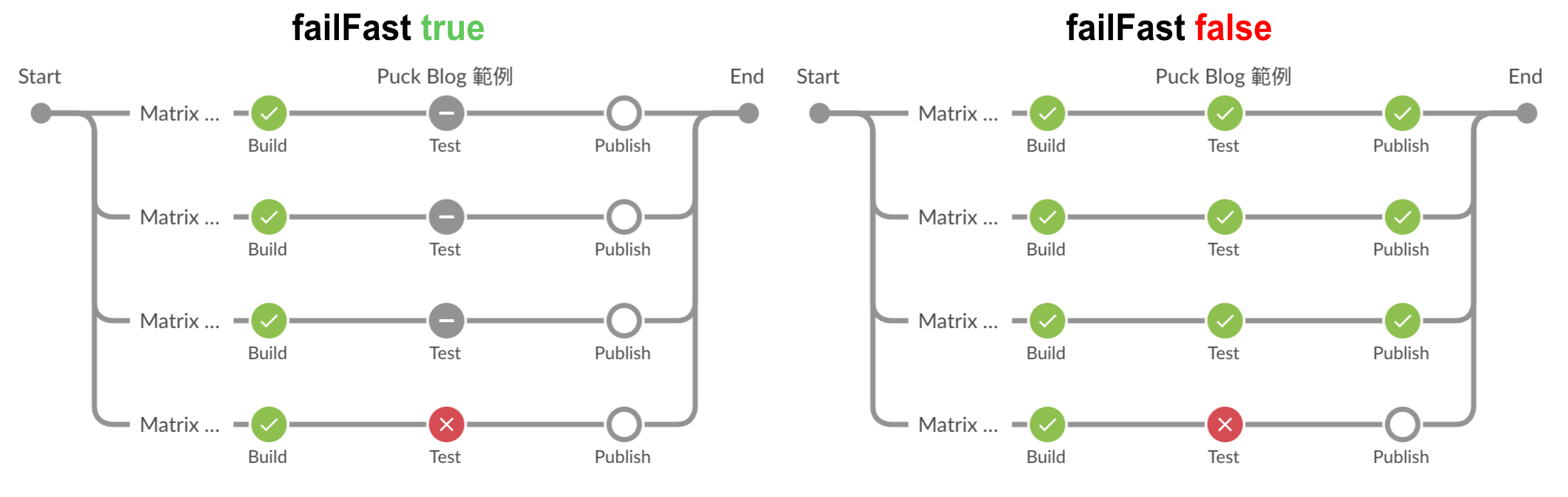
pipeline {
agent any
stages {
stage('Puck Blog 範例') {
failFast true
matrix {
axes {
axis {
name 'PLATFORM'
values 'mac', 'windows'
}
axis {
name 'BROWSER'
values 'chrome', 'firefox'
}
}
stages {
stage('Build') {
steps {
echo "Do Build for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
stage('Test') {
steps {
echo "Do Test for ${PLATFORM} - ${BROWSER}"
script {
if (PLATFORM == 'windows' && BROWSER == 'firefox') {
sh 'exit 1' // 模擬發生了錯誤
}
}
sleep(5)
}
}
stage('Publish') {
steps {
echo "Do Test for ${PLATFORM} - ${BROWSER}"
sleep(5)
}
}
}
}
}
}
}Dynamic Parallel Stages
我們可以利用 for-loop 來動態建立 Parallel Stages,可以增加執行的變化。
以下是一個簡單的例子。
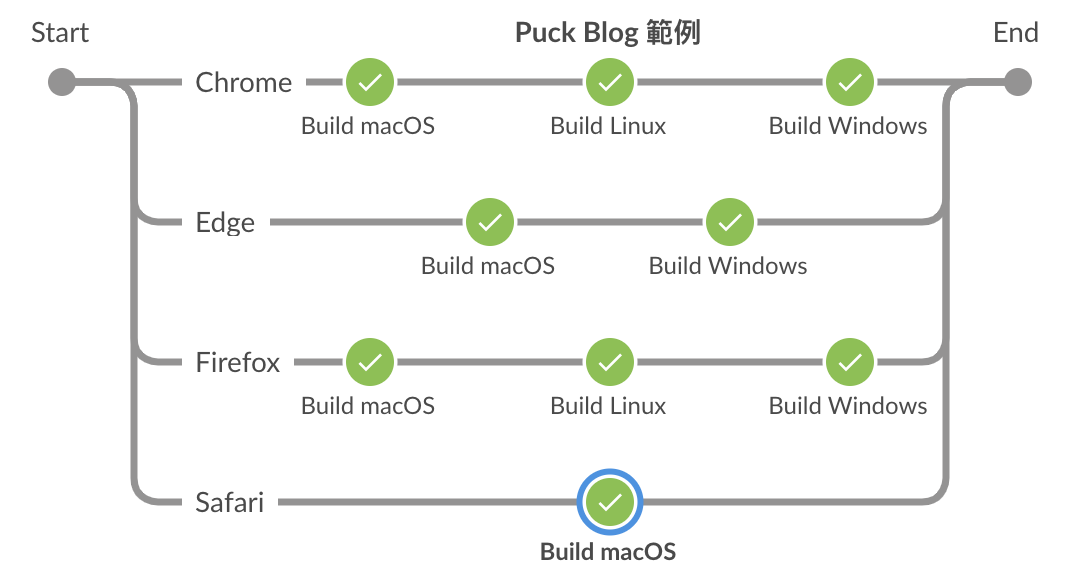
def browsers = ['Chrome', 'Edge', 'Firefox', 'Safari']
pipeline {
agent any
stages {
stage('Puck Blog 範例') {
steps {
script {
def jobs = [:]
for (int i = 0; i < browsers.size(); i++) {
// 這裡必需放到一個變數裡,否則 i 在執行時就不見了
def browser = browsers[i]
// 以 browser 為分支名稱建立 stage
jobs[browser] = {
stage(browser) {
stage('Build macOS') {
echo "Build ${browser} for macOS"
sleep(5)
}
if (browser == 'Chrome' || browser == 'Firefox') {
stage('Build Linux') {
echo "Build ${browser} for Linux"
sleep(5)
}
}
if (browser != 'Safari') {
stage('Build Windows') {
echo "Build ${browser} for Windows"
sleep(5)
}
}
}
}
}
parallel jobs
}
}
}
}
}該使用哪一種方式?
我自己是偏向使用 parallel,因為他自由度比較高,也可以透過變數去動態產生,而 matrix 就沒辦法帶變數。
遇到需要比較複雜的設定時,我使用變數來儲存設定,並透過變數去動態產生 stage,將來要改設定時也比較方便且直觀。
如下範例:
def data = [
[
enable: true,
name: 'xxxx',
// ...
],
[
enable: true,
name: 'xxxx',
// ...
]
]
pipeline {
agent any
stages {
stage('Puck Blog 範例') {
steps {
script {
def jobs = [:]
for (int i = 0; i < data.size(); i++) {
def item = data[i]
jobs[item.name] = {
stage(item.name) {
// ...
}
}
}
parallel jobs
}
}
}
}
}另外是使用 parallel 可以自訂分支名稱,在 Blue Ocean 中跟 matrix 比起來比較清楚,從前面 parallel 與 matrix 例子中就可以看到一個分支名稱是可以自訂的,而另一個是固定的不能改。
不過還是要看使用情況,但主要還是以 parallel 為首選。
參考資料
Puck Wang
Hi! 我是 Puck Wang,這個部落格的作者,是一位全端網站開發者,常使用 .Net 和 React 進行開發,專注於架構研究,你可以在這個部落格看到我精選的筆記內容,希望對你會有所幫助。
更多關於我的訊息,可至關於關於頁面。